本文共 1426 字,大约阅读时间需要 4 分钟。
一、top1和top5
top1-就是预测的label取最后概率向量里面最大的一个作为预测结果,如果你的预测结果中概率最大的那个分类正确,则预测正确。否则预测错误。
top5-就是最后概率向量最大的前五名中,只要出现了正确概率即为预测正确。否则预测错误。
二、Precision、Recall和Accuracy
2.1 Precision和Recall
假如一个用户向系统提交一个查询(例如“什么是猫”),系统返回了一系列查询的结果,这些结果是系统根据用户提交的信息,判定出来系统内所有跟这个信息有关的结果。
 在这个结果里,黄色的部分是系统返回的结果,绿色的部分是总共对用户有用的结果。两者的交集,也就是中间的部分,通常叫做True Positive(TP)。而返回结果的剩下部分,则是False Positive,意思就是说这些本身是对用户没啥用的,但是系统判定这些对用户有用并且提交给用户了。而绿色部分剩下的,是False Negative,这一部分是本来对用户有用的结果,但是被系统判定没用。剩下的灰色部分就是真的没啥用的结果。
在这个结果里,黄色的部分是系统返回的结果,绿色的部分是总共对用户有用的结果。两者的交集,也就是中间的部分,通常叫做True Positive(TP)。而返回结果的剩下部分,则是False Positive,意思就是说这些本身是对用户没啥用的,但是系统判定这些对用户有用并且提交给用户了。而绿色部分剩下的,是False Negative,这一部分是本来对用户有用的结果,但是被系统判定没用。剩下的灰色部分就是真的没啥用的结果。 Precision就是 T P T P + F P \frac{TP}{TP+FP} TP+FPTP,也就是提交给用户的结果里面,究竟有多少是对的,或者反过来说,我们给了用户多少没用的垃圾。Recall是 T P T P + F N \frac{TP}{TP+FN} TP+FNTP,也就是一共有这么多的有用结果,系统究竟能判定出来多少是有用的(能够检测出来多少?),或者反过来说,我们究竟丢了多少有用的。这两个数是成对出现,单独出现没有意义。
这两个检测指标是成对出现的,单独出现没有意思。为什么这么说?一个例子是我们可以轻轻松松将recall提高到100%,那就是不管用户查询什么,都将系统中所有的文档提供给用户,这样肯定不会丢东西,但是这样用户也没办法得到好的结果
2.2 为什么不用准确率(accuracy)?
准确率,也就是accuracy,就是 T P + T N N \frac{TP+TN}{N} NTP+TN,也就是系统究竟做对了多少,如果是对于平衡样本来说在,这个没问题。但是对于样本不平衡的情况,这就不行。例如信息检索,有99.999%的信息对用户都没用,而且大部分系统肯定都能判别出来这些没用,
二、mAP(mean average precision)
多标签图像分类(Multi-label Image Classification)任务中图片的标签不止一个,因此评价不能用普通标签图像分类的标准,即mean accuracy,该任务采用的是和信息检索中类似的方法-mAP(mean Average Precision)
以下是mAP的计算方法:
- 首先用训练好的模型得到所有测试样本的confidence score,每一类(如car)的confidence score保存到一个文件中,假设共有20个测试样本,每个的id、confidence score和ground truth如下:

- 接下来对confidence score排序,得到:

- 然后计算precision和recall,这两个标准的定义如下:
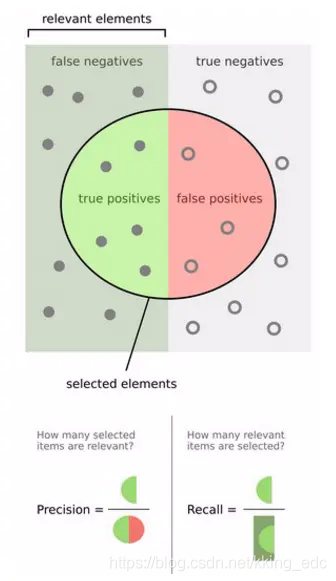 上图比较直观,圆圈内(true positives+false positives)是我们选出的元素,它对应于分类任务中我们取出的结果,比如对测试样本在训练好的car模型上分类,
上图比较直观,圆圈内(true positives+false positives)是我们选出的元素,它对应于分类任务中我们取出的结果,比如对测试样本在训练好的car模型上分类,
转载地址:http://uctx.baihongyu.com/